
Find the right balance between agility and stability with SRE
If you wish to achieve customer centricity in your solutions, you could focus on operational practices, such as site reliability engineering (SRE), to meet this goal.
At cVation (part of Skaylink) we have a strong DevOps focus, aiming to address tasks with a customer-centric approach. Our main goal is to reconcile the interests of development and operations, even when they clash (e.g., the desire for unrestricted launches versus the reluctance to change a working system).
Site Reliability Engineering
SRE was pioneered by Google, where it was developed to manage their large-scale systems. However, the principles and practices of SRE as an engineering discipline have been adopted by many other organizations to improve the reliability of their software systems.
In summary, SRE is a set of practices and principles which combines software engineering and operations to ensure the reliability, performance, and availability of complex software systems through the use of automation, monitoring, incident response and continuous improvement.
Site Reliability Engineering (SRE) is devoted to help organizations sustainable achieve the proper level of reliability in their systems. An important aspect, is to find the right balance between agility and stability.
Responsibilities of the SRE teams are:
Availability / reliability / latency / performance / efficiency / change management / monitoring / emergency response and capacity planning of their services.
To allow a team to do this on a large project we aim to automate or cut out anything repetitive. The SRE team will emphasize that the systems design will work reliably amidst frequent updates from development teams.
For the SRE team to be able to adapt to a changing system, it needs to be designed with observability in mind, i.e., having a high level of monitoring which means logging enough data in the system to be able to do proper investigations. This allows the SRE team to constantly assess new user flows and monitor critical paths for the project.
Agility versus Stability
Historically the division between Development and Operation has resulted in a clash of what is most important: Either agility in releasing new features or maintaining stability for the customer.
The SRE concept allows us to discuss this conundrum, by utilizing Service Level Indicators (SLIs), Service Level Objectives (SLOs) and a resulting error budget. The SLI can be interpreted as monitoring an important user flow, e.g., in an IoT setup. Here it could be the user installing a sensor and confirms it being alive in a management portal. The SLO would then be the rules for latency, availability, and correctness that the user should expect.
The SLO allows the SRE team and the business to communicate and agree on concrete numbers of uptime and performance. The difference between the measured SLI and the defined SLO is the error budget. When we are performing better than agreed the development teams can ship features ASAP. However as soon as our budget is negative, the SRE team is charged with halting releases, investigating issues, removing or tasking a development team to remove impediments. Basically, a negative SLO means that the project needs to focus on quality. Thus, the battle between operation and development can be reduced to being over or under our agreed SLO.
To explicitly define the error budget, we can interpret it as how much “unreliability” is available in the measured time frame. This is an important notion, since all deployments introduce a risk for unreliability, even the biggest companies such as Microsoft can release something that despite all tests and best practices can result in an outage. The SRE team is often seen as only focusing on user-flows related to availability or latency, but a user-flow could also be seen from a business perspective such as revenue or churn. Let us examine this with the following example, where we have a Machine Learning setup which generates recommendations for our users.
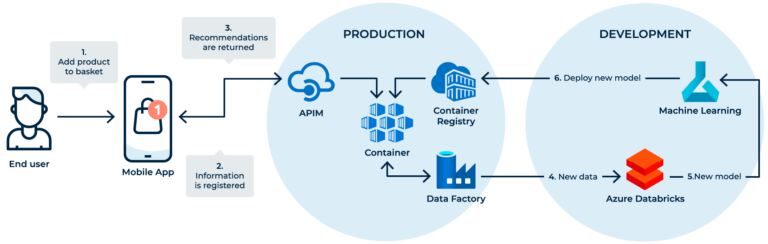
This mock-up is a pipeline which combines user events, and purchases, on a weekly basis. To refresh a Machine Learning model that generates recommendations. If the pipeline fails, the model will be trained on old obsolete data, and the user might no longer be interested in the recommended items. Thus, it could directly affect the revenue stream of the company. In such a scenario, the final business outcome would be decreasing conversion rates and increasing churn rates, which is an important user-flow to monitor for the business.
Value to gain from SRE driven teams
It is not a goal or a value to have many SLOs, but rather to have the right ones. A good indicator to decide if a SLO is relevant is: “if you can’t ever win a conversation about priorities by quoting a particular SLO, it’s probably not worth having that SLO”. Therefore, the SRE team can bring immense value for the organization in standardizing and translating business requirements into code. The SRE team is staffed with developers who can contribute to infrastructure, CI/CD pipelines and business features.
The value we have seen from an SRE team is, continuously driving structural improvements of the project. This enables other development teams to deliver value faster, since underlying technical requirements affecting the entire project can be handled by a specific team. In different projects the SRE team have illustrated their worth by conducting load tests, monitoring SLOs, acting as a CoE team, implementing cross functional features for the development teams. This has allowed us to catch issues and identify bottlenecks before they are manifested for the user.
The final and important element of the SRE team is that any incident can be identified and prioritized immediately. This does not mean that the SRE team needs to solve the underlying issue. They can delegate this part of the job to other teams, but they will be bringing production forward, to ensure it is functioning. You should always prefer to move forward instead of rolling back changes, to keep agility in the project.
How to get started
To emphasize why and which concrete value an SRE team delivers, I want to itemize it in the following points:
-
Achieve an improved understanding of the system in production
-
Ensure short time of reaction to issues fast
-
Clear communication of requirements and performance with the business
To achieve this in an organization we emphasize systematic automatic testing of the system, going through the entire chain of unit tests, integration tests, end to end tests, load tests and finally chaos engineering. This allows you to understand how prepared you are for issues and disasters. The reason for us here at cVation (part of Skaylink) to be able to do all this, is our strong foundation in DevOps and SRE.
We achieve a high level of control and trust in our releases, because we have removed any toil or manual steps needed for deployment, relying fully on automation in CI/CD pipelines.
SLA contracts
The observant reader would notice that we have not discussed Service Level Agreements (SLA), which is what most will be familiar with. The SLA is an explicit or implicit contract with your users that includes consequences of meeting (or missing) them. The SLA describes the whole system with a specific measure towards the users, but it is not something that can be readily materialized into actions for the team. This is what the SLOs have, the objectives the team must comply with for the agreement (SLA) is uphold.
Finally, the actual number that the SRE team is looking at, is the SLI. The SRE team does not typically get involved in constructing SLAs, because SLAs are closely tied to business and product decisions.
A post-mortem culture - without blame
Despite all these efforts, problems will unfortunately still arise in production. To reduce the risk of a similar problem occurring in production, we have a culture of no-fault post-mortems. The exercise is done without pointing fingers, instead we focus on what and how. Then we follow four steps:
-
Define and describe the problem
-
Implement tests that replicate the problem
-
Create a solution
-
Implement the solution in production
In this way, we ensure that a similar problem cannot arise, and by defining the problem, we can uncover deficiencies in our processes that need to be addressed. This results in a clear picture of what happened. Furthermore, it supports clear and precise communication to stakeholders, assuring them that we have identified a solution to the root causes.
We find this is a great way to drive the transformation forward on large projects, regardless of the maturity level of your business. The value you achieve is immediate and the work can continue without some of the typical clashes between development and operations.
Would you like to know more about SRE?
If you would like to find out more about the full potential of SRE or need general support in transforming your development department or your company in favour of truly agile processes, we will be happy to help you. Our experts look forward to hearing from you!